Edge Intelligence makes it fast and easy to analyze vast amounts of geographically distributed data.
Overcome the constraints associated with traditional big data warehouses, database design and edge computing architectures.
Gain a competitive advantage by extracting the maximum value from your data.
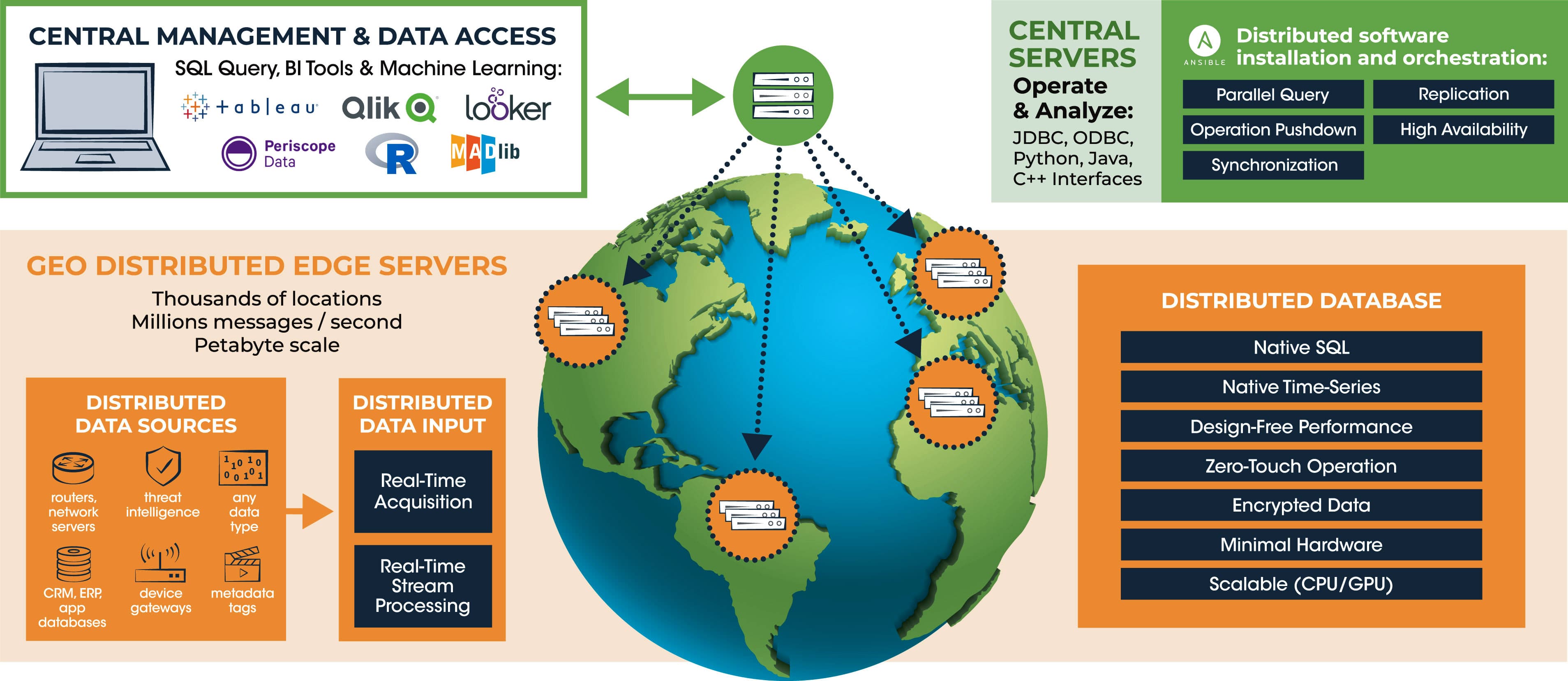

Transferring volumes of data across geographies takes too long, is expensive and increases privacy concerns. Instead of shipping data to perform analytics, distribute and federate analytics at the edge. Extend analytics close to all of your different sources of data by leveraging low cost edge computing and hybrid cloud resources – scalable to thousands of discrete locations. Even though data resides across many locations, the platform makes it appear as though it was all in a single location. Command, control and querying of all data is all done through a centralized portal.

Queries are performed using SQL commands with the full functionality of a relational database. Standard interfaces and programming languages (JDBC/ODBC, Python, Java, C++) allow for easy integration with BI, machine learning and DevOps tools. Users can realize immediate value without having to develop any specialized expertise.
The similarities with SQL stop here. Large volumes of data can load in real-time, similar to NoSQL, and the software is scalable to accept millions of messages per second. We’ve developed a patented, scalable distributed database architecture that pre-optimizes data for the fastest response to all query types and formats – with flexible support for both structured and semi-structured data formats.
Orders of magnitude improvements in query response times are realized when compared to other data architectures optimized for a specific data structure such as a row or column store. Data can be distributed across the globe, yet queries performed on billions of data records are responded to in seconds.

Our patented, scalable technique exploits modern hardware characteristics and stores data by access intent instead of utilizing indexes or partitions. No specialized processors, memory or storage is required. The system is cost-effective for long-term data retention from gigabytes to petabytes. Multi-source data correlation and stream processing, using SQL syntax, can be performed on all incoming data in real-time without the need for large amounts of memory.
The platform is designed for zero-touch operation. There is no need to design, tune or optimize for performance. No query tuning, indexing, partitioning or schema design is required. Software is propagated to each location automatically and data is seamlessly replicated and synchronized. Data that has aged for a specified time can be removed without intervention. Load balancing and fault tolerance is inherent to the system design to ensure high availability.

The platform is inherently secure. Encryption is applied to all in-flight and at-rest data. All internal communications within the platform are authenticated. Access to data directly from any node is prohibited. Data can be contained within any geography to address privacy concerns and compliance requirements.
New data sources can be added in the future without worry. The system is able to accept data of any size and format, with flexible means to get data into the system such as JSON messaging and CSV/TSV files. Fast changing analytic and reporting requirements can be supported without making design changes to the system. New sources of data and device types, including the types of queries & reports that might need to be run in the future, are supported without modification or redesign.