
Your data is unique. Where it must be collected and stored is too. To minimize latency, cost and privacy concerns, you’ll likely want data to reside in geographic locations that are as close as possible to where your own devices, machines and sensors are generating data. Thousands of locations can be supported, so feel good knowing you can distribute data across as many different buildings, cities, and countries that you’d like based on your own requirements.
For each location, you can decide on either physical or cloud-based storage and compute resources. As a guideline, each physical edge server can store several hundred terabytes of data and collects data at rates of hundreds of thousands of messages per second. On-demand and reserved infrastructure available within public cloud data centers are supported as well. A hybrid approach combining both physical and cloud-based resources is supported.
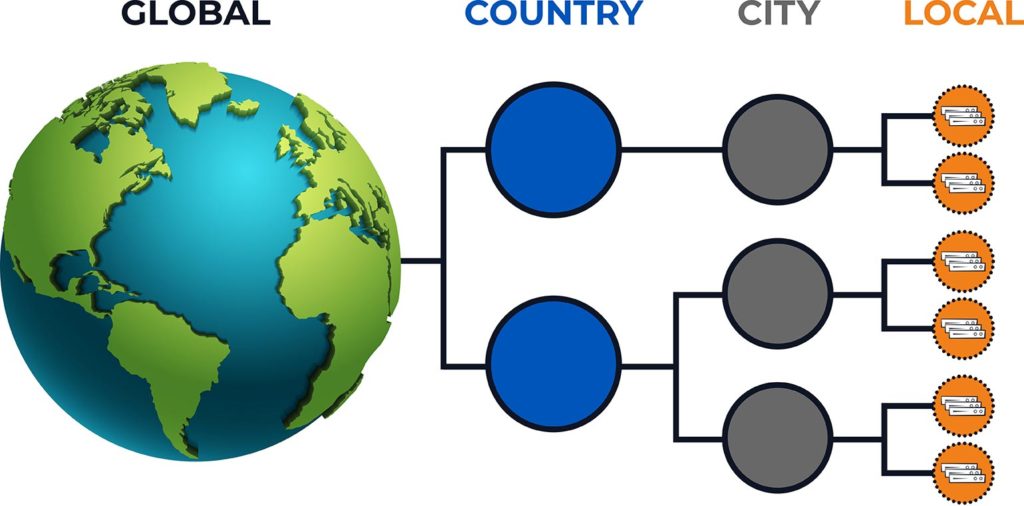
You’re provided with your own secure and authenticated portal access. An Ansible environment is used to automate the software installation to each geographical location where storage and compute have been provisioned. All operations issued through the centralized portal are guaranteed to propagate to all of the necessary locations ensuring that all changes across all edges are made only once.
Within the portal, you create your own unique edge topology with an arbitrary shape and depth. This allows analysis for individual locations, groups or as a whole. Locations can be added or removed with ease as requirements change. Data sources are configured centrally using an extensible library of adaptors.

Structured and semi-structured data is collected at each edge location using flexible messaging schemes. This allows the system to intake newly generated data directly from an unlimited number of devices and other data sources all at once. In addition, historical data stored within business applications and legacy systems can be imported into the network using a variety of configurable file formats. This eliminates potential data silos which lead to lost insight. Encryption is applied to all in-flight and at-rest data.
The system acts autonomously and is designed to provide fast, reliable performance. Once collected, data is pre-optimized to provide an optimal response to any query type. No performance tuning is required. Data is automatically replicated and synchronized for optimal performance and availability. Data can be automatically aged and deleted from the system, or held indefinitely, without manual intervention.

Standard SQL queries are issued through the centralized portal interface, using full-featured, standard commands. Industry standard interfaces allow for the easy integration with industry leading BI tools such as Tableau, Looker and Qlik. Standard APIs are available to export analytical results into existing workflows and dashboards.
SQL-based stream processing can be automatically performed on incoming data in real-time, while analyzing against historical data stored within the system. In-database distributed machine learning can be leveraged for algorithm training and refinement.